
Using Python multiprocessing to optimize a problem
Introduction
This is the final part of the Python puzzle game series. In the first part we learnt to create a tiles puzzle game using Turtle module. And then in the second part created an algorithm to find a solution of the puzzle. But the algorithm can be optimized further, and in this article we will look at some of the ways we can achieve that.
To make sense of this article, I suggest that first you go through the previous posts in this series (if you haven't already done so).
The need for further optimization
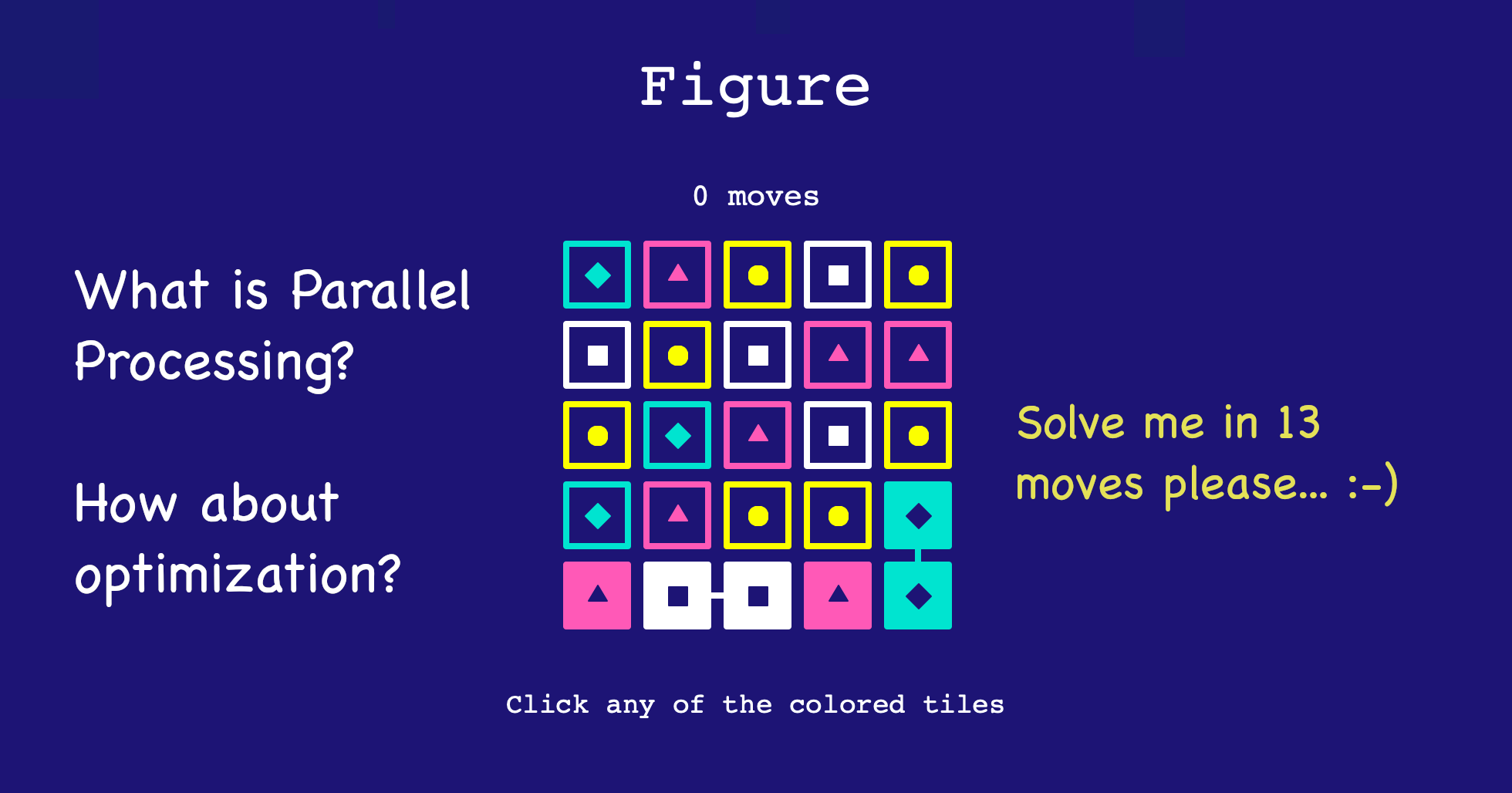
Let's run the final code from the previous post on a different puzzle which requires more number of moves.
play([
['hot pink', 'turquoise', 'yellow', 'white', 'turquoise'],
['white', 'hot pink', 'turquoise', 'yellow', 'hot pink'],
['white', 'yellow', 'hot pink', 'white', 'yellow'],
['hot pink', 'yellow', 'white', 'hot pink', 'white'],
['turquoise', 'turquoise', 'yellow', 'hot pink', 'yellow']
])
These are the results
start time: 0.113825565
changed min_moves to: 16, 4000001111223334, time: 0.12959095
changed min_moves to: 15, 400000114313122, time: 0.135476449
changed min_moves to: 14, 40000432310211, time: 0.483449261
changed min_moves to: 13, 4433100000122, time: 49.005072394
No more jobs: final count: 2012130, time: 324.622757167
result of operation: {'min_moves': '4433100000122', 'min_moves_len': 13, 'count': 2012130}
So even with our previous optimization, we ran close to 2 million end to end sequences, and it took us around 5 minutes and 25 seconds to finish the job. Do remember that we're only looking for one valid solution, and not trying to find all possible sequences of the same length (and believe me, there will be many such sequences).
So, can we do something more?
Well, what if we could run some of these jobs in parallel? That should save us some time, don't you think? Let's find out.
Modified play & find_min_moves functions
We will be using multiprocessing module to run multiple processes in parallel to see if it can make a difference. The reason for going with multiple processes instead of multiple threads is simple, our code is pure compute problem with no IO related tasks. Multiple threads make sense where there are some wait times involved (as in the case of IO tasks, like downloading something from internet etc).
from timeit import default_timer as timer
import copy
import multiprocessing as mp
import os
import AutoPlay
def find_min_moves(task):
# Create an internal job list for this process and add the incoming task to it
jobs = [task]
pid = os.getpid()
result = {'min_moves': None, 'min_moves_len': 0, 'count': 0, 'pid': pid}
print(
f'entered pid: {pid}: for moves: {task["curr_move"]}, time: {timer()}')
while True:
# See if we've any jobs left. If there is no job, break the loop
job = jobs.pop() if len(jobs) > 0 else None
if job is None:
print(
f'No more jobs: pid: {pid}, final count: {result["count"]}, time: {timer()}')
break
# Handle the current job. This will take of the combinations till its logical
# end (until the board is clear). Other encountered combinations will be added
# to the job list for processing in due course
final_moves_seq = AutoPlay.handle_job_recurse(
job, jobs, result['min_moves_len'])
result['count'] += 1
# If the one processed combination has minimum length, then that is the minimum
# numbers of moves needed to solve the puzzle
if result['min_moves_len'] == 0 or (final_moves_seq is not None
and len(final_moves_seq) < result['min_moves_len']):
result['min_moves'] = final_moves_seq
result['min_moves_len'] = len(final_moves_seq)
print(
f'pid: {pid}, changed min_moves to: {result["min_moves_len"]}, {final_moves_seq}, time: {timer()}')
return result
def play(colors):
# Single game object which holds the tiles in play,
# and the current connections groups and clickables
game = {
'tiles': [],
'clickables': [],
'connection_groups': []
}
# Set the board as per the input colors
for col in range(AutoPlay.MAX_COLS):
game['tiles'].append([])
for row in range(AutoPlay.MAX_ROWS):
tile = {'id': (row, col), "connections": [],
"clickable": False, "color": colors[col][row]}
game['tiles'][col].append(tile)
# Go through the tiles and find out the connections
# between them, and also save the clickables
for col in range(AutoPlay.MAX_COLS):
AutoPlay.process_tile(game, 0, col)
start = timer()
print(f'start time: {start}')
# Create as many tasks as there are connection groups.
# We're using deepcopy to create a deeply cloned game
# object for each task. The current move is the first
# entry of every connection group (the lowest column
# index in the bottom row)
tasks = []
for connections in game['connection_groups']:
g = copy.deepcopy(game)
tasks.append(
{'game': g, 'curr_move': connections[0], 'past_moves': None})
# Get a managed pool from multiprocessing, and distribute the tasks to these
# pools. By default it will create processes equal to the number returned by
# os.cpu_count().
with mp.Pool() as pool:
results = pool.map(find_min_moves, tasks)
print('got results:', timer())
for result in results:
print('result:', result)
with mp.Pool() as pool:
gives us a managed pool which cleans after itself.
results = pool.map(find_min_moves, tasks)
is a blocking function which takes care of distributing the tasks to the processes from the pool. For every process, find_min_moves function is called with one task from the tasks list.
The result
If we try to call our play function now, we will get the below RuntimeError (on Windows and macOS).
An attempt has been made to start a new process before the
current process has finished its bootstrapping phase.
This probably means that you are not using fork to start your
child processes and you have forgotten to use the proper idiom
in the main module:
if __name__ == '__main__':
freeze_support()
...
The "freeze_support()" line can be omitted if the program
is not going to be frozen to produce an executable.
As the error is saying, we need to protect the entry point of our program, else it will enter into an endless loop while spawning child processes. Let's modify the calling part
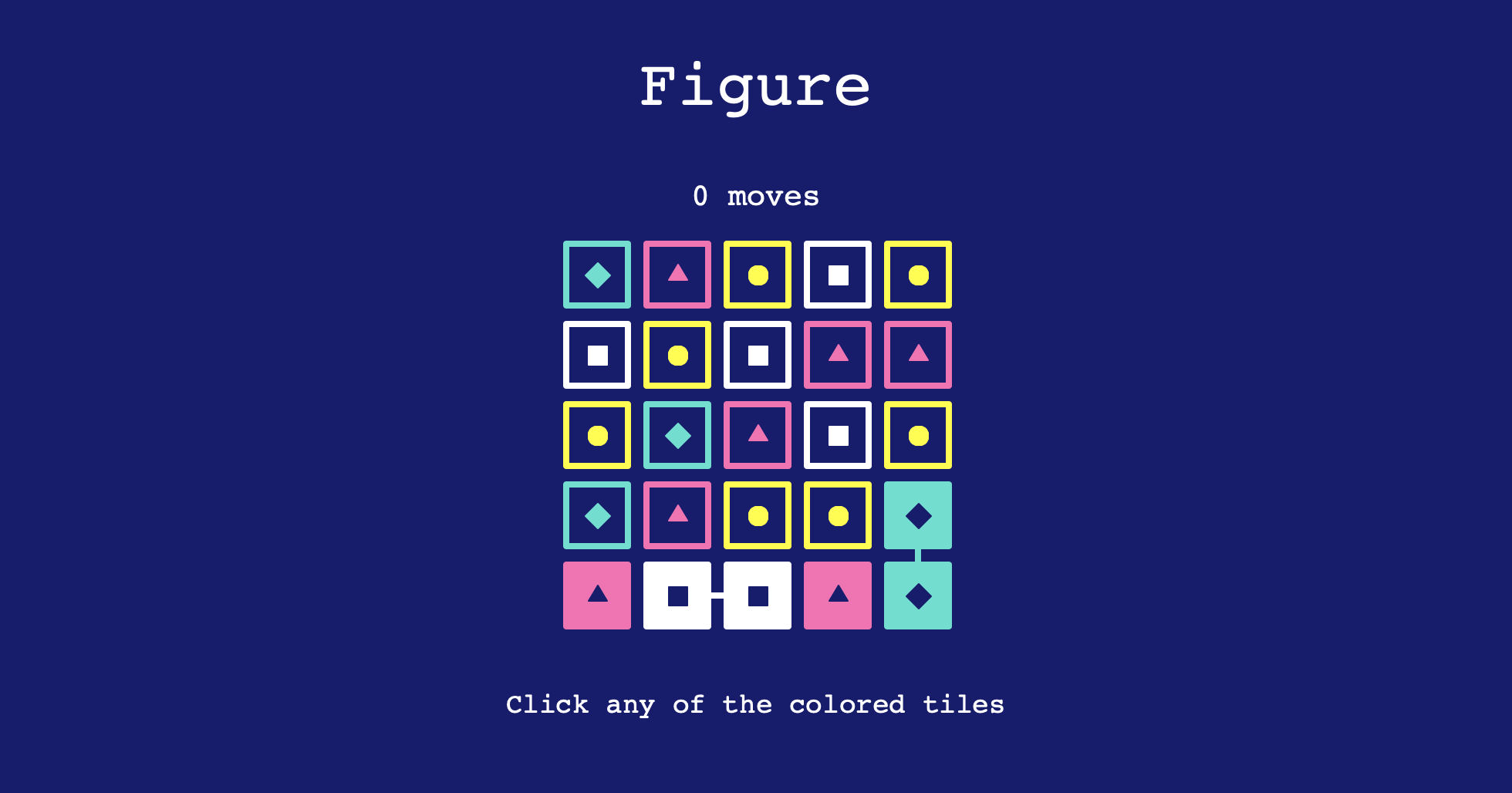
if __name__ == '__main__':
play([
['hot pink', 'turquoise', 'yellow', 'white', 'turquoise'],
['white', 'hot pink', 'turquoise', 'yellow', 'hot pink'],
['white', 'yellow', 'hot pink', 'white', 'yellow'],
['hot pink', 'yellow', 'white', 'hot pink', 'white'],
['turquoise', 'turquoise', 'yellow', 'hot pink', 'yellow']
])
And here are the results of the execution
start time: 0.05643949
entered pid: 39066: for moves: (0, 0), time: 0.120805656
pid: 39066, changed min_moves to: 18, 000001111223334444, time: 0.128779476
pid: 39066, changed min_moves to: 17, 00000111122344334, time: 0.130322022
pid: 39066, changed min_moves to: 16, 0000011112423334, time: 0.131969189
pid: 39066, changed min_moves to: 15, 000001144313122, time: 0.209503056
entered pid: 39067: for moves: (0, 1), time: 0.193182385
pid: 39067, changed min_moves to: 16, 1000001223334444, time: 0.203432333
pid: 39067, changed min_moves to: 15, 100000122344334, time: 0.206294855
pid: 39067, changed min_moves to: 14, 10000012423334, time: 0.209911962
entered pid: 39068: for moves: (0, 3), time: 0.2225178
entered pid: 39069: for moves: (0, 4), time: 0.22732867
pid: 39068, changed min_moves to: 18, 300000111122334444, time: 0.254337267
pid: 39068, changed min_moves to: 17, 30000011112244334, time: 0.268903578
pid: 39069, changed min_moves to: 16, 4000001111223334, time: 0.272185431
pid: 39069, changed min_moves to: 15, 400000114313122, time: 0.278042101
pid: 39068, changed min_moves to: 16, 3000001114431224, time: 0.337434568
pid: 39068, changed min_moves to: 15, 300000114131224, time: 0.351929327
pid: 39069, changed min_moves to: 14, 40000432310211, time: 1.06737366
pid: 39068, changed min_moves to: 14, 30000423104211, time: 1.918205703
pid: 39067, changed min_moves to: 13, 1004430003122, time: 2.159644669
pid: 39066, changed min_moves to: 14, 00004432310211, time: 4.574963226
No more jobs: pid: 39067, final count: 171415, time: 52.145841877
pid: 39069, changed min_moves to: 13, 4433100000122, time: 96.061340938
No more jobs: pid: 39069, final count: 418533, time: 115.766546083
pid: 39068, changed min_moves to: 13, 3431000001224, time: 217.433144061
No more jobs: pid: 39068, final count: 1166097, time: 256.900814533
No more jobs: pid: 39066, final count: 2631991, time: 479.720000441
got results: 479.826363948
result: {'min_moves': '00004432310211', 'min_moves_len': 14, 'count': 2631991, 'pid': 39066}
result: {'min_moves': '1004430003122', 'min_moves_len': 13, 'count': 171415, 'pid': 39067}
result: {'min_moves': '3431000001224', 'min_moves_len': 13, 'count': 1166097, 'pid': 39068}
result: {'min_moves': '4433100000122', 'min_moves_len': 13, 'count': 418533, 'pid': 39069}
Wow! This is bad... We took close to 8 minutes, to finish executing the program, and did almost 4.4 million end to end sequences. Please notice that the program was running in parallel for sometime with process ids 39066-39069. We found 3 different sequences all giving us 13 as the minimum number of moves.
So what went wrong as compared to the previous case?
The thing is, in the case of a single process, the min_moves variable was same for all the executions, but here that is not the case. We had different variables (result["min_moves_len"]) for different starting moves. So, even though the code ran in parallel, individually every process did more end-to-end sequences because of the forced silos.
**How do we fix this? **
We somehow need to have a common min_moves variable between these processes. We can't simply use a global variable for the same as different processes have their own memory space. We need to take help from multiprocessing module itself for achieving data sharing.
The final optimization
We will use a synchronized shared object Value() for storing the min_moves_len, and then we will use it in our processes to make a decision. Since knowing the current min moves length in our processes is sufficient for us, and so, using Value makes more sense (for storing a number, and it is faster too) as compared to other ways of sharing data between processes.
Modified play and find_min_moves functions
We are using another function called init_globals to initialize each process with a min_moves global variable for that process. We need to pass this function as initializer while creating the processes pool. We also create one Value() object (min_val = mp.Value('i', 0), where 'i' denotes a signed integer), and pass that to the initializer function as initargs.
def init_globals(min_val):
global min_moves
min_moves = min_val
# To use the min_moves variable we just need to use its `value` attribute
# like, min_moves.value
def find_min_moves(task):
# Create an interal job list for this process and add the incoming task to it
jobs = [task]
pid = os.getpid()
result = {'min_moves': None, 'min_moves_len': 0, 'count': 0, 'pid': pid}
print(
f'entered pid: {pid}: for moves: {task["curr_move"]}, time: {timer()}')
while True:
# See if we've any jobs left. If there is no job, break the loop
job = jobs.pop() if len(jobs) > 0 else None
if job is None:
print(
f'No more jobs: pid: {pid}, final count: {result["count"]}, time: {timer()}')
break
# Handle the current job. This will take of the combinations till its logical
# end (until the board is clear). Other encountered combinations will be added
# to the job list for processing in due course
final_moves_seq = AutoPlay.handle_job_recurse(
job, jobs, min_moves.value)
result['count'] += 1
# If the one processed combination has minimum length, then that is the minimum
# numbers of moves needed to solve the puzzle
if min_moves.value == 0 or (final_moves_seq is not None
and len(final_moves_seq) < min_moves.value):
min_moves.value = len(final_moves_seq)
result['min_moves'] = final_moves_seq
result['min_moves_len'] = min_moves.value
print(
f'pid: {pid}, changed min_moves to: {result["min_moves_len"]}, {final_moves_seq}, time: {timer()}')
return result
def play(colors):
# Single game object which holds the tiles in play,
# and the current connections groups and clickables
game = {
'tiles': [],
'clickables': [],
'connection_groups': []
}
# Set the board as per the input colors
for col in range(AutoPlay.MAX_COLS):
game['tiles'].append([])
for row in range(AutoPlay.MAX_ROWS):
tile = {'id': (row, col), "connections": [],
"clickable": False, "color": colors[col][row]}
game['tiles'][col].append(tile)
# Go through the tiles and find out the connections
# between them, and also save the clickables
for col in range(AutoPlay.MAX_COLS):
AutoPlay.process_tile(game, 0, col)
start = timer()
print(f'start time: {start}')
# Create as many tasks as there are connection groups.
# We're using deepcopy to create a deeply cloned game
# object for each task. The current move is the first
# entry of every connection group (the lowest column
# index in the bottom row)
tasks = []
for connections in game['connection_groups']:
g = copy.deepcopy(game)
tasks.append(
{'game': g, 'curr_move': connections[0], 'past_moves': None})
min_val = mp.Value('i', 0)
# Get a managed pool from multiprocessing, and distribute the tasks to these
# pools. By default it will create processes equal to the number returned by
# os.cpu_count(). Also initialize min_moves global for each process using a
# Value() shared object
with mp.Pool(initializer=init_globals, initargs=(min_val,)) as pool:
results = pool.map(find_min_moves, tasks)
print('got results:', timer())
for result in results:
print('result:', result)
The result
start time: 0.057702366
entered pid: 39420: for moves: (0, 0), time: 0.14133282
pid: 39420, changed min_moves to: 18, 000001111223334444, time: 0.149716058
pid: 39420, changed min_moves to: 17, 00000111122344334, time: 0.151552746
pid: 39420, changed min_moves to: 16, 0000011112423334, time: 0.153877295
entered pid: 39419: for moves: (0, 1), time: 0.195602278
pid: 39419, changed min_moves to: 15, 100000122344334, time: 0.203628052
pid: 39419, changed min_moves to: 14, 10000012423334, time: 0.205814167
entered pid: 39421: for moves: (0, 3), time: 0.175389625
entered pid: 39422: for moves: (0, 4), time: 0.230612233
pid: 39419, changed min_moves to: 13, 1004430003122, time: 2.607543404
No more jobs: pid: 39419, final count: 171415, time: 61.43746481
No more jobs: pid: 39422, final count: 210959, time: 77.746001708
No more jobs: pid: 39421, final count: 536682, time: 144.053795224
No more jobs: pid: 39420, final count: 895965, time: 210.756625277
got results: 211.040409704
result: {'min_moves': '0000011112423334', 'min_moves_len': 16, 'count': 895965, 'pid': 39420}
result: {'min_moves': '1004430003122', 'min_moves_len': 13, 'count': 171415, 'pid': 39419}
result: {'min_moves': None, 'min_moves_len': 0, 'count': 536682, 'pid': 39421}
result: {'min_moves': None, 'min_moves_len': 0, 'count': 210959, 'pid': 39422}
Yay! We have made progress. Now it takes only 3 minutes 31 seconds to do the job (as compared to around 5 minutes 25 seconds with single process), with around 1.81 million end to end sequences.
The CPU count and its implications
Please note that all of the results were collected on my macbook pro having a dual core processor. So os.cpu_count() returns 4 in my case, 2 logical cores for each physical core. That is why 4 processes are getting created in the above examples. We can play around with the number of processes and see if that makes any further difference. In my case, I've found that running 2 processes gives me the best result (The value may be different for you, depending on the number of cores your workhorse has).
Changing one line in the play function
with mp.Pool(processes=2, initializer=init_globals, initargs=(min_val,)) as pool:
We get the following results:
start time: 0.103170482
entered pid: 39540: for moves: (0, 0), time: 0.226195533
pid: 39540, changed min_moves to: 18, 000001111223334444, time: 0.238348483
pid: 39540, changed min_moves to: 17, 00000111122344334, time: 0.239980543
pid: 39540, changed min_moves to: 16, 0000011112423334, time: 0.265787826
entered pid: 39541: for moves: (0, 1), time: 0.239561019
pid: 39541, changed min_moves to: 15, 100000122344334, time: 0.246132816
pid: 39541, changed min_moves to: 14, 10000012423334, time: 0.247991375
pid: 39541, changed min_moves to: 13, 1004430003122, time: 1.319787871
No more jobs: pid: 39541, final count: 171415, time: 27.815133454
entered pid: 39541: for moves: (0, 3), time: 27.816530592
No more jobs: pid: 39541, final count: 533304, time: 135.0901852
entered pid: 39541: for moves: (0, 4), time: 135.090335439
No more jobs: pid: 39541, final count: 207783, time: 172.9650854
No more jobs: pid: 39540, final count: 895570, time: 183.029733485
got results: 183.21633772
result: {'min_moves': '0000011112423334', 'min_moves_len': 16, 'count': 895570, 'pid': 39540}
result: {'min_moves': '1004430003122', 'min_moves_len': 13, 'count': 171415, 'pid': 39541}
result: {'min_moves': None, 'min_moves_len': 0, 'count': 533304, 'pid': 39541}
result: {'min_moves': None, 'min_moves_len': 0, 'count': 207783, 'pid': 39541}
Only 2 processes with pids 39540 & 39541 were used in this case. When the process with pid 39540 was going through sequences starting with 0 column id, process with pid 39541 finished processing the sequences starting with remaining column ids (1, 3 & 4 in this case). It took nearly 3 minutes (so a saving of around 30 seconds) to finish the job, with nearly the same 1.8 million end-to-end sequences.
And we've have a winner in our midst :-)
Conclusion
That was one long article with a lot of code, and repeated optimizations. I'm sure further optimizations can be done. I also tried to distribute jobs between different processes using a shared queue object (sgain from multiprocessing), but didn't get favorable results. There is one Manager class also available in the multiprocessing module, which allows us to create shared proxy objects. Using that we wouldn't need to use the initializer and initargs, and can share the object as argument like we are doing for tasks, but the documentation says that it will be slow, so I haven't covered that (of course I tried it myself :-)).
There must be other ways to solve the problem, after all, there are multiple ways to solve any problem in general, and programming in particular. It might be possible that there is a very simple trick to solve this instantly.
Do share how would you solve this problem?
Please hit me up if you have any questions, or if you find any error anywhere.
Enjoy :-)